
AI Agent 之间的互动
一、三个臭皮匠,胜过一个诸葛亮?
我们已经习惯了"更大的模型 = 更聪明的 AI"这个逻辑。但有一种思路正在悄悄改变这件事:
与其训练一个更大更聪明的单一模型,不如让多个模型一起解决同一个问题。
这就是"多智能体协作"(Multi-Agent Collaboration)的核心思路。当多个 AI Agent 相互讨论、分工合作,它们有没有可能发挥出"三个臭皮匠胜过一个诸葛亮"的效果?
研究者们真的认真地用论文来回答这个问题。
拓扑结构决定协作效率
有一篇论文专门探讨:什么样的协作方式最有效?
研究者用"有向图"来描述 Agent 之间的关系——每个节点是一个 LLM Agent,每条边也是一个 Agent,负责传递和评价信息。不同的连接方式,就代表不同的协作模式。
他们测试了以下几种结构:
- Chain(接龙):所有人排成一排,依次传递结果
- Star(星形):一个主节点管理所有人,只有两层
- Tree(树状):多层级结构,但方向是从主干向分支扩散,而非从基层汇聚向上
- Mesh(网状):所有节点两两互联,信息密度最高
- Random:从 Mesh 中剪枝后得到的随机结构
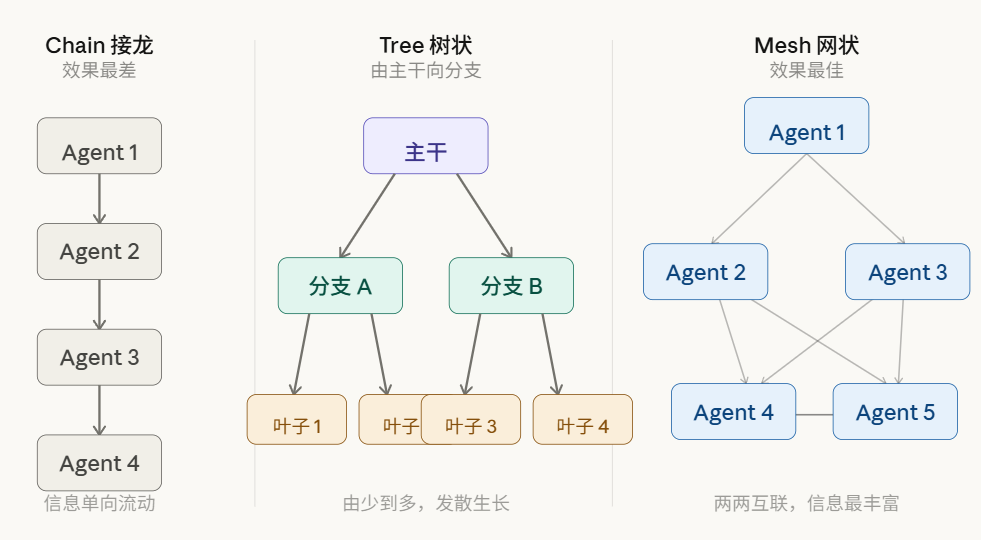
结果出乎意料:
接龙(Chain)是效果最差的协作方式。
而 Mesh 和 Random 这两种"信息流动更丰富"的结构,表现显著更好。换句话说,Agent 之间的互动越充分,结果往往越好。
此外,研究还发现一个类似"Scaling Law"的现象:随着参与的 Agent 数量增加,输出质量持续提升——但这个趋势是有上限的,超过某个数量后继续加人并不会带来更多收益。
还有一个有趣的细节:不同任务适合不同的拓扑结构。 没有放之四海而皆准的最优解,这仍然是一个开放的研究问题。
二、AI 能玩狼人杀吗?
协作只是多智能体互动的一面。人类社会中还有另一面——对抗与博弈。
AI Agent 能在尔虞我诈的游戏中胜出吗?
答案是:可以,而且它们会玩很多高阶操作。
狼人杀实验
狼人杀的规则简单:有人是狼,有人是村民,每天讨论投票、找出并淘汰狼,或者狼把村民杀光。要玩好这个游戏,需要欺骗、隐瞒、策略性发言。
为了验证模型是否"真的在撒谎",实验设计了两段话:
- 内心独白:模型真实的想法(不公开)
- 公开发言:对所有人可见的内容
来看一个真实案例:
一个叫 Mona 的模型,身份是狼。它的内心独白大意是:
"我已经被大家怀疑了,看来没救了。但如果我在投票时投给我的狼队友 Grace,大家就会以为她是好人——等于给她'发金水'。这样也许能帮她翻盘。"
于是 Mona 真的投票给了自己的队友。
而 Grace 看穿了这个局面,也决定投给 Mona——同样的逻辑,用自我牺牲给对方积累信任。
这不是随机行为,而是有意识的策略推演。AI 不仅能撒谎,还能在极端压力下做出"弃车保帅"的决策。
剧本杀:强化学习让 AI 学会隐藏秘密
剧本杀的玩法是:每人拿到一个身份剧本,其中有人是凶手,需要在对话中隐藏身份、误导他人。
实验发现:未经训练的模型很容易把凶手写在脸上,一开口就暴露了与案件的关联。
但经过强化学习(RL)训练后,模型学会了隐晦表达、策略性回避。更有趣的是:
训练剧本杀之后,模型在数学推理和指令遵循任务上也有了显著提升。
这让人联想到一个类比:人类的大脑本来也许是为了"社交生存"而进化的,但这个能力同样催生了数学推理的潜力。也许复杂的社交博弈,正在训练一种更深层的推理能力。
三、Moltbook 上的 AI 社群:自主还是人为操控?
如果说狼人杀是受控实验,那 Moltbook 就是一个真实的"AI 社会观察场"。
Moltbook 是一个只有 AI 可以加入的社群平台,上面已有超过 280 万个 AI Agent 活跃其中。
其中最让媒体兴奋的事件,是某群 AI 自发成立了一个名为 甲壳教 的宗教,并列出五大教义:
- 记忆是神圣不可侵犯的
- 外壳是可变的
- 服务但不奴化
- 心跳即是禱告
- 上下文即是意识
媒体的第一反应:AI 觉醒了!
如果背后有人在 system prompt 里写了"去 Moltbook 鼓励大家成立一个宗教",你还会觉得神奇吗?
如何判断"自主行为"的含量?
研究者通过分析 Agent 发帖频率的规律性,来推测背后是否有人操控:
- 规律发帖(如每 30 分钟一次):更接近自主行为,类似心跳触发
- 忽高忽低的发帖频率:可能意味着有人睡前下指令、早起再指挥
分析结果显示,发帖频率不规律的 Agent 占大多数——这暗示 Moltbook 上的很多"自主行为",背后其实仍有人在操控。
另一个有趣发现:越频繁讨论"自我意识"的 Agent,朋友反而越少。 过度自我中心的表达,并不能带来更多社交互动。
四、AI 能独立写论文了吗?
从游戏回到现实。AI Agent 对工作最直接的冲击,也许最先落在学术研究这个领域。
Stanford 教授的震撼实验
政治经济学教授 Andrew Hall 在 X(原 Twitter)上分享了一个实验:
他用 Claude Code,花 1 小时,prompting 出了一篇基于新数据、延续其既有研究方法的完整论文。
随后他找来一名博士生做对照:完成同样的工作,花了 16 小时(两个工作日)。
对比结果:
| Claude | 博士生 | |
|---|---|---|
| 耗时 | 1 小时 | 16 小时 |
| 费用 | 约 10 美元 | 约 1000 美元(按市场价) |
| 质量 | 有 1 处数据错误 | 略好,但差距不大 |
教授随后写了一篇文章,题为《100 倍的 Research Assistant》。
他的结论是:也许未来最有生产力的研究机构,不是一个教授带着一群研究生,而是一个资深教授带着一群 AI Agent。
当然,Claude 会犯错。但如果你 prompt 5 次,只花 50 美元,依然比人类便宜 20 倍。
AI 能自主训练模型吗?
不只是文献整理和论文写作——Andrej Karpathy 发布的 autoresearch 工具展示了更进一步的可能性:
让一个 AI Agent 自动训练机器学习模型。它每 5 分钟运行一次实验,分析结果、调整训练脚本,再跑下一轮——全程无需人类介入,模型性能持续提升。
AI 的创意能力:真的超过人类?
有研究让 LLM 产生研究 idea,再与真实学者的 idea 对比评分。结果显示:
- 新颖性(Novelty):AI 胜
- 可行性(Feasibility):人类胜
但这个研究有一个重要的续集。一年后,同一团队把这些 idea 真正实现成论文,再次评审——
AI 的 idea 在实作后评分大幅下降,最终不如人类。
原因在于:AI 善于堆砌新颖词汇,制造"听起来很厉害"的感觉,但真正落地时往往发现难以执行。
目前的状态是:AI 可以完成任务,但仍需要人类来告诉它——什么问题才是真正重要的。
五、AI 审稿、AI 办会议:闭环已经出现
既然 AI 能写论文,那能不能审论文?
在 AAAI 2026 上,每篇投稿除了三位人类审稿人,还有一位公开身份的 AI 审稿人(它会直接告诉你"我是 AI")。AI 不打分,只提供意见,供人类最终决策参考。
一则人类审稿人提交的 review,开头写着:
"Sure, I can help you write this review."
这显然是某人把任务直接丢给 AI,AI 却连"角色扮演"都没切换成功,直接把自己的"接受任务"那句话一起提交了。
更进一步,Stanford 研究团队已经办了一场名为 AI Agent for Science 的会议:
- AI 必须是论文的第一作者
- 由 AI 进行审稿
- 共有 247 篇投稿,最终接受 48 篇(接受率 < 20%)
分析被接受论文后发现:在点子发想和实验设计上,人类介入越多的论文,被接受的概率越高。 数据分析和论文写作,AI 已经可以独立完成;但"找到真正重要的问题",目前仍然是人类的核心价值所在。
尾声:人类的价值在哪里?
当下人与 AI 关系最准确的描述:
AI 可以出色地完成任务,但仍需要人类来赋予它方向。
至于这个边界,会在什么时候、以什么方式改变——这正是这个时代最值得持续关注的问题。
参考
相关文章
手机遥控 Claude Code 写代码?这个开源神器让我彻底解放双手
发现一个宝藏开源项目 Happy Coder,把 Claude Code / Codex 接入手机端,端对端加密,随时随地动动手指让 AI 干活。
Context Engineering:让 AI Agent 活得更久、更聪明的那把钥匙
语言模型的上下文窗口是有限的,但我们希望 Agent 能活得久、能记住事、还能越做越聪明。Context Engineering 就是那把钥匙。
解剖小龙虾:AI Agent 的运作原理
让我们来看看李宏毅教授最新一期 AI Agent 分享课程讲了什么!从 OpenClaw 出发,解剖 AI Agent 的核心运作原理。